Jak dobrze korzystać z Cursora (cz. 1)
Od grudnia ’24 przerzuciłem się z GitHub Copilot na Cursor i zdecydowanie nie żałuję. Umożliwia on bowiem bardzo wygodne korzystanie ze wsparcia różnych modeli AI podczas pracy nad kodem zasadniczo zwiększając możliwości programisty i tempo jego pracy. Jednak dobre wykorzystanie mocy tego narzędzia wymaga umiejętnego wykorzystania jego funkcji oraz przestrzegania jednej, bardzo ważnej zasady.
To nadal ja programuję
To najważniejsza zasada! Nadal musisz rozumieć co robisz i wiedzieć jak kod, który tworzysz działa oraz dlaczego. Do tego zaś konieczna jest podstawowa wiedza programistyczna i choćby minimum doświadczenia. W przeciwnym razie AI bardzo szybko wpuści „vibe-codera” w maliny.
Przykład: tworzę aplikację, w której świadomie nie stosuję ORM zamiast tego używając własnej klasy obsługującej baze danych poprzez zapytania SQL. Przy tworzeniu jednej z fukncji AI wygenerowało mi kod, który zawierał wprowadzenie ORM – i to konkretnego. Gdybym nie rozumiał co się dzieje, czym jest ORM (a także dlaczego go w danej chwili w tym projekcie nie chcę) to oczywiście nic bym nie zauważył bo proponowany kod był spójny i działał. Tyle, że nie był spójny z moją decyzją i z tym jak napisana była reszta aplikacji co w przyszłości prowadziłoby to problemów.
Zatem korzystając ze wsparcia AI musisz zachować „kierowniczą rolę”, kontrolować co się dzieje.
Oczywiście, poziom tej kontroli nie musi być taki sam w całej aplikacji. Ja nauczyłem się dzielić sobie projekt na trzy „strefy”:
- core, w którym chcę rozumieć każdą linijkę,
- obszar pośredni, gdzie chcę rozumieć jak działają wszystkie metody/funkcje ale nie muszę znać szczegółów oraz
- resztę, gdzie idę na pełny – jak to się teraz mówi – „vibe coding”.
Przykład: w aplikacji, którą aktualnie rozwijam core to system agentów AI oparty o framework AG2. Tam zachowuję pełną kontrolę, nawet rzeczy takie jak refaktoryzacja wykonuję całkowicie ręcznie. Owszem, używam wsparcia AI na przykład do pomocy w wyszukiwaniu błędów ale w trybie, w którym nie wprowadza ono samo żadnych zmian do kodu. Strefa pośrednia to np. klasa zajmująca się obsługą logiki interakcji z użytkownikiem. A „reszta” to HTML i kod w JavaScript, który stanowi interfejs aplikacji – tam nawet nie wiem jakie funkcje JS są stosowane i do czego, bo jest to w sumie mało istotne – ważne, że działa.
Planowanie działań
W przypadku drobnych zmian – np. poprawa jakiegoś niewielkiego błędu albo drobna zmiana istniejącej funkcjonalności – można korzystać ze wsparcia AI po prostu w trybie „Agent” pisząc mu o co chodzi.
Jednak w przypadku zmian większych – np. dodanie dużej funkcjonalności czy większa przebudowa logiki aplikacji – zdecydowanie należy oddzielić planowanie od realizacji jeśli chcemy korzystać ze wsparcia AI w pisaniu kodu (czyli poza „core”).
Przeprowadzając większą zmianę postępuję zatem następująco:
Krok 1: piszę obszerny prompt opisujący tło (jaki jest stan obecny? co ogólnie chcę osiągnąć?) a następnie w ogólnym zarysie w jakich krokach zamierzam osiągnąć mój cel – co wprowadzić lub zmienić w aplikacji, jaką ma to mieć architekturę, z jakich dodatkowych, nowych rozwiązań skorzystać itp.
Na tym etapie dyskutuję z modelem, proszę o opinię, o zaprezentowanie możliwych alternatyw itp. Wsparcie AI polega więc nie na generowaniu kodu, ale pomocy w projektowaniu zmiany. Na tym etapie korzystam z trybu „Ask” lub własnego trybu („custom mode”) o nazwie „Analysis”.
Krok 2: Kiedy uznam, że osiągnąłem zadowalający plan proszę model o zapisanie go do dokumentu, wraz z informacją o celu do osiągnięcia a także o przygotowanie listy etapów. Etapy są numerowane, na każdym etapie mamy opis tego co zostanie po jego zakończeniu osiągnięte a także (w niektórych przypadkach) pseudokod lub wręcz kod w języku docelowym pokazujący kluczowe struktury tego, co zamierzam zbudować. Każdy etap powinien kończyć się tak, że coś jest weryfikowalnie ukończone, działające.
Dokument ten następnie starannie czytam i w razie potrzeby poprawiam ręcznie. Zostaje on umieszczony w odpowiednim katalogu w projekcie (zwykle /doc).
Krok 3: Tworzenie kodu – wskazując modelowi dokument z planem (korzystając z funkcji Cursor umożliwiającej dodawanie konkretnych plików do kontekstu) proszę o wygenerowanie kodu dla konkretnego etapu. Pracujemy wspólnie aż dany etap będzie działał (co zwykle obejmuje także testy). Idąc w ten sposób, etap po etapie osągam bardzo zadowalające rezultaty przy dużych zmianach.
Tylko postępując w opisany sposób ograniczymy problem jakim jest gubienie się przez naszych pomocników AI podczas pracy nad większymi zmianami. Gubią się oni dlatego, że… tracą kontekst. Ściślej rzecz ujmując, nasze początkowe polecenia i wymagania wychodzą poza okno kontekstowe w efekcie czego model „nie pamięta” już w jakim celu rozpoczęto zmiany. A wtedy zaczyna się gubić lub produkować coś, co jest niespójne z naszymi zamierzeniami. Jeśli AI ma plan, to którego może się odwołać (plan jest w kontekście, który wybieramy w okienku chata Cursor), a my sterujemy nim każąc mu wykonywać kolejne etapy AI „rozumie” co się dzieje i czego oczekujemy w następnym kroku.
Dodatkowo wcześniejsze planowanie umożliwia wykorzystanie wiedzy i inteligencji modeli dla przedyskutowania z nimi opcji możliwych rozwiązań operując na wyższym poziomie abstrakcji. Dzięki temu wspólnie przygotowany plan jest wyższej jakości, a co za tym idzie lepszy jest także efekt końcowy.
AI też potrzebuje dokumentacji
Zakładamy zwykle, że dane treningowe modelu zawierają całą kopalnię wiedzy na temat języków programowania oraz różnych bibliotek i narzędzi. Tak jest w istocie szczególnie, że większość dokumentacji a także spora część kodu źródłowego, z którego korzystamy, dostępne są bezpłatnie i bez ograniczeń w Internecie stanowią więc pozbawioną problemów prawnych, łatwo dostępną część puli danych treningowych.
Wszelako warto pamiętać, że przy tak ogromnej bazie wybranie właściwych danych jest dla modelu pewnym wyzwaniem. A poza tym o ile same języki programowania zmieniają się raczej niewiele a przy tym rzadko ich twórcy wprowadzają zmianę powodującą brak wstecznej zgodności to niektóre biblioteki i frameworki rozwijają się szybkim tempie. W efekcie dane, które nasz model czerpie o nich ze swoich danych treningowych bardzo szybko będą po porostu nieaktualne!
Na szczęście Cursor przychodzi tu z pomocą umożliwiając stworzenie RAG (vectore store) z wybraną przez nas dokumentacją. W Cursor preferences w zakładce Features po przewinięciu w dół mamy sekcję Docs. Używając guzika Add new doc możemy dołożyć tam kolejne dokumentacje np. właśnie dla naszych bibliotek.

Warto zauważyć, że Cursor próbuje przeczytać i zwektoryzować wskazaną stronę „w głąb”, czyli także jej podstrony. Warto potem klikając w ikonkę otwartej książki (patrz niżej) sprawdzić co zostało przetworzone, a więc jest dostępne dla modeli.
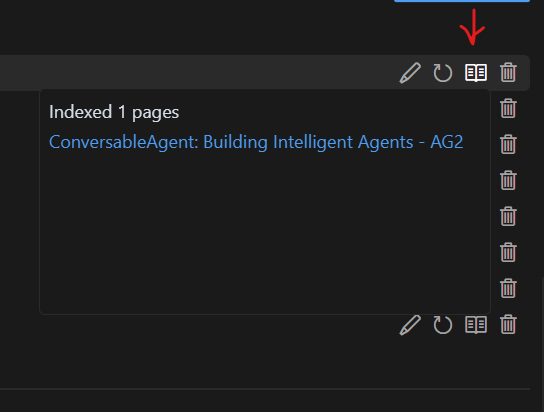
W niektórych przypadkach konieczne jest podanie „ręcznie” dokumentacji „strona po stronie”, ale zdecydowanie warto to zrobić dla kluczowych dla naszego projektu (lub jego etapu w przypadku projektów większych) bibliotek i narzędzie. Od tego momentu wszystkie modele jakie udostępnia Cursor, a które wspierają korzystanie z bazy klienta będą realnie korzystać z tej dokumentacji.
Pamiętać przy tym trzeba o dwóch rzeczach:
- po pierwsze, baza dokumentacji nie zmienia się wraz z projektem tj. nie jest zapisana w plikach projektu czyli jeżeli pracujemy nad różnymi projektami może to być nieco kłopotliwe bo lepiej jeśli dokumentacja jest dostosowana do potrzeb projektu,
- po drugie, Cursor sam nie odświeży dokumentacji na nowszą szczególnie jeśli np. zmienią się linki. Jeśli więc to coś, do czego dokumentację wykorzystujemy, będzie miało nową wersję to najpewniej musimy usunąć poprzednią wersję dokumentacji i wprowadzić nową.
W następnym odcinku: o trybach (modes)
Ten artykuł zrobił sie już dość długi, dlatego postanowiłem podzielić go na odcinki. W następnym odcinku opiszę dokładniej jak korzystać z trybów (ang. modes) pracy z modelem oferowanych przez Cursor, w tym także jak skorzystać z możliwości zdefiniowania własnych trybów.
You May Also Like
